



DirectX 11显卡几何性能应用体验
 近日,在网络上掀起了真假DirectX 11的争论,争论的焦点是部分玩家认为NVIDIA GF100是真正意义上针对DirectX 11规范设计的全新架构,而AMD的DirectX 11产品是在原有DirectX 10产品架构上优化而来的产物。那么,这个有关DirectX 11显卡之争的焦点是什么?为何玩家有如此大的分歧?本刊曾在4月下对GeForce GTX 480显卡做了详细测试,其中也谈到了DirectX 11的部分。今天,我们就这个话题进一步深入,一起来就真假DirectX 11的话题进行分析和测试。
近日,在网络上掀起了真假DirectX 11的争论,争论的焦点是部分玩家认为NVIDIA GF100是真正意义上针对DirectX 11规范设计的全新架构,而AMD的DirectX 11产品是在原有DirectX 10产品架构上优化而来的产物。那么,这个有关DirectX 11显卡之争的焦点是什么?为何玩家有如此大的分歧?本刊曾在4月下对GeForce GTX 480显卡做了详细测试,其中也谈到了DirectX 11的部分。今天,我们就这个话题进一步深入,一起来就真假DirectX 11的话题进行分析和测试。
事实上,在IT界类似“真假DirectX 11”之争的讨论从来没有停止过,例如曾经闹得沸沸扬扬的桥接和原生SATA方案之争。有一种观点认为,虽然桥接SATA方案的性能不是佳,但它推出时间快,能在第一时间让用户体验新技术带来的新应用。而另外一种观点则认为,原生SATA方案虽然推出时间慢,但性能更佳,兼容性更好,原生芯片方案是未来的发展趋势。单就这两种方案的设计思路而言,并没有绝对的好与坏,终的结果肯定是大家都转向“原生”方案。“真假DirectX 11”之争是否也如此呢?我们下面的分析将告诉你答案。
Tessellation(曲面细分)—DirectX 11的关键特性
本刊曾经在2010年2月上对DirectX 11显卡的效率和画质进行了全面测试,结论是DirectX 11的执行效率很高,这主要归功于DirectX 11 API中的Tessellation(曲面细分)和DirectCompute 11。借助DirectCompute 11,可以在游戏中实现电影级别的景深效果、更符合真实环境的高清晰环境光遮蔽、顺序无关透明化。而曲面细分技术,本刊曾经多次对该技术进行解析。毫不夸张地说,微软在DirectX 11 API中引入曲面细分技术,就好比将一个迷路的孩子领回了家。因为AMD(ATI)早在2001年就已经研发出相关技术,但当时没有引起业界的重视,没有被纳入任何一个图形计算和编程的API之中。随着图形核心的发展,微软开始意识到几何性能计算的重要性,并终于在DirectX 11 API中引入了曲面细分技术。这预示着GPU的几何引擎将在未来扮演更加重要的角色。当然,DirectCompute 11和曲面细分都只是DirectX 11中的部分规范,并不能以是否支持它们为由来判断真假DirectX 11。那么曲面细分技术究竟能为我们带来什么呢?

时至今日,我们仍然在许多游戏大作里面发现,主角的脑袋是方形的,胳膊是多边形的,这和现实状况完全不相符。这是因为在3D建模的时候,由于CPU性能有限,无法使用更多的三角形去建立模型,以至于出现上述情况。但曲面细分技术的引入有望改变这一切,它主要依赖GPU进行几何运算,以实现更丰富的模型。
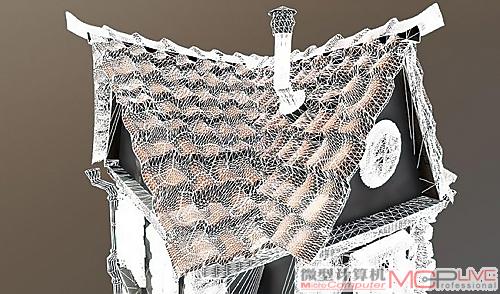
加入曲面细分技术后,物体更加真实。
我们用一个例子来看看曲面细分技术的含义。假设你有一个球体和若干方形瓷砖,现在请你使用这些瓷砖尽可能紧密包裹球体,尽可能覆盖更多的球体表面积,你会怎么做呢?如果直接将瓷砖覆盖至球体表面后会发现,它已经成了一个棱角分明的棱台,几乎失去了原有球体的造型。这是因为方砖是平面,篮球是曲面,平面只能以切面形式和曲面上的一个点接触。但如果尝试将瓷砖砸碎,使它变成一个个面积非常小的方块呢?是的,当用面积足够小的瓷砖去包裹球体时,包裹出的篮球就越精细。因此,你可以将曲面细分理解为将原有的平面砸碎。然后用这些“碎片表面”进一步贴合原有曲面。砸得越碎,细分的表面越多,就越接近目标曲面!更多有关曲面细分技术的解析请参考本刊5月上《几何性能的跃进时代 从曲面细分看GPU图形和游戏的发展》一文。
源于设计理念的不同—NVIDIA和AMD的DirectX 11图形架构分析
借助曲面细分技术,我们可以极大地改善游戏画质。解决的办法虽然有了,但GPU的性能却没有跟上脚步。这是因为进行大量曲面细分的计算会极大耗费GPU几何性能,而过去业界一直强调GPU的阴影、贴图能力,忽略了几何性能,只设计了一个前端控制电路模块用于几何性能的计算。如今,NVIDIA和AMD都意识到了这个问题,在DirectX 11产品上都针对几何计算进行了优化,但二者的思路和实现方法却大不一样。

在NVIDIA方面,它认为成熟的GT200架构已经无法适应大规模的几何计算,因此对支持DirectX 11的GF100图形架构进行了全新设计,哪怕产品推出时间较晚也在所不惜。而专门用于几何计算的Raster Engine和PolyMorph Engine就是GF100架构上的关键和创新设计。Raster Engine分散在四个GPC内,PolyMorph Engine则分散在每组SM里面,这种层层递进的并行架构设计的几何性能计算效率更佳。在AMD方面,它强调抢先发布DirectX 11产品,从而快速占领市场。它的DirectX 11产品的架构是在成熟的RV770架构基础上,通过相对简单的核心堆积、添加DirectX 11指令的方式而成。它有一个用于几何计算的前端控制模块,拥有用于几何计算的运算单元(Tessellator(镶嵌器)+Vertex Assembler(顶点装配器)+Geometry Assembler(几何装配器)+Rasterizer×2+Hierarchial-Z×2,Rasterizer+Hierarchial-Z对应GF100的Raster Engine,Tessellator+Vertex Assembler+Geometry Assembler对应GF100的PolyMorph Engine)。我们可以将Cypress的图形架构中的Rasterizer(光栅器)和Hierarchial-Z(多级Z缓冲模块)看成是GF100中的Raster Engine;将Cypress的图形架构中的Vertex Assembler(顶点装配器)、Geometry Assembler(几何装配器)和Tessellator(镶嵌器)看成是GF100中PolyMorph Engine,对应顶点拾取、曲面细分、观察口转换、属性设置和流式输出,它们的功能类似。
从用于几何计算的几何单元数量来看,NVIDIA的GF100远超过AMD的Cypress。GF100拥有四个Raster Engine,Cypress实现类似功能的单元只有两个(Rasterizer+Hierarchial-Z)×2,比例为4∶2。GF100拥有16个PolyMorph Engine,而Cypress实现类似功能的单元只有一个(Tessellator+Vertex Assembler+Geometry Assembler),比例为16∶1。单从图形架构和专用于几何计算单元的数量来看,GF100的几何计算性能将大大超过Cypress。
性能实测—谁对曲面细分支持得更好
那么,对几何计算进行优化设计的全新架构GF100的实际性能能否超越相对保守的Cypress?GF100在几何单元数量上的优势能否转化为性能上的优势?我们将通过基于DirectX 11的应用测试来寻找答案。
|
测试成绩对比 | ||
|
|
索泰GTX 480极速版 |
Radeon HD 5870 |
|
《Unigine Heaven Benchmark 2.0》 | ||
|
1920×1080 Shader(High)、 |
42.6 |
22 |
|
1920×1080 Shader(High)、 |
73 |
55 |
|
《异形大战铁血战士》 | ||
|
1920×1080 VeryHigh |
101 |
101 |
|
1920×1080 VeryHigh 16AF |
79.5 |
82 |
|
《科林麦克雷:尘埃2》 | ||
|
1920×1080 UltraHigh |
91.1 |
69.6 |
|
1920×1080 UltraHigh 4AA |
78 |
63.3 |
|
1920×1080 UltraHigh 8AA |
69.2 |
61 |
|
《潜行者:普里皮亚季》 | ||
|
1920×1080 UltraHigh |
70.6 |
64.9 |
|
1920×1080 UltraHigh 4AA |
43 |
37 |
|
《地铁2033》 | ||
|
1920×1080 VeryHigh 16AF |
47.2 |
23.7 |
|
1920×1080 VeryHigh 4AA 16AF |
43 |
17 |
测试包括两个方面,一则是通过《Unigine Heaven Benchmark 2.0》软件来考量两者的几何计算性能,“DirectX 11+Shader(High)+Tessellation(Extreme)”是高画质+极致Tessellation等级+DirectX 11的设置,这是考验它们在极致Tessellation画面下的性能;“DirectX 11+Shader(High)+Tessellation(Disabled)”是高画质+关闭Tessellation+DirectX 11的设置,这是考验它们在DirectX 11模式下,关闭Tessellation特效后(此时Occlusion等其它DirectX 11特效仍然存在)执行其它DirectX 11特效的效率。通过这两种不同模式的测试,我们将对两者的DirectX 11性能,尤其是Tessellation性能一目了然。二则是通过大量DirectX 11游戏来看看它们在实际游戏中的表现。在测试产品方面,我们以索泰GTX 480极速版为例来看看它和同级别Radeon HD 5870的性能差距。
GF100的曲面细分性能全面超越
在《Unigine Heaven Benchmark 2.0》1920×1080+DirectX 11+Shader(High)+Tessellation(Disabled)模式下,索泰GTX 480极速版的性能领先Radeon HD 5870约33%。这说明测试中虽然关闭了曲面细分,但索泰GTX 480极速版凭借全新设计的图形架构在执行其它DirectX 11特效时依然游刃有余;在1920×1080+DirectX 11+Shader(High)+Tessellation(Extreme)模式下,游戏中存在大量高级别的曲面细分特效,对显卡的几何计算性能提出了很高的要求。Radeon HD 5870在图形架构、几何计算单元数量不足的劣势被体现出来,它的凭借帧率只有22fps,画面不时有比较明显的停顿感。而索泰GTX 480极速版的帧数则达到了42.6fps,领先Radeon HD 5870约93%,体现了它的架构和几何计算单元数量上的优势。
DirectX 11游戏:GF100优势依旧
DirectX 11游戏和《Unigine Heaven Benchmark 2.0》的测试结果类似,索泰GTX 480极速版在DirectX 11游戏的测试中依旧表现出了不错的势头,例如在《潜行者:普里皮亚季》测试中,索泰GTX 480极速版领先Radeon HD 5870约12%。同时我们也注意到,在DirectX 11游戏测试中,索泰GTX 480极速版的领先幅度有所下降。这是因为GF100架构主要针对曲面细进行了优化,实际DirectX 11游戏中除了加入曲面细分这项DirectX 11技术以外,也加入了其它DirectX 11、DirectX 10甚至DirectX 9.0c技术,Radeon HD 5870依靠频率的优势缩小了差距。此外,游戏开发商也考虑到目前显卡几何性能并不算高,如果在游戏中加入大量极致的曲面细分技术会使显卡不堪重负,因此实际游戏中的曲面细分效果不如《Unigine Heaven Benchmark 2.0》。
总结:曲面细分,未来游戏发展趋势
图形核心在经历了过分强调阴影贴图的时代以后,终于迎来了理性的回归——重拾几何性能。NVIDIA和AMD也在相关的DirectX 11产品上进行了设计和优化,但思路和产品的终性能表现却大不一样。
AMD强调快速推出DirectX 11产品,Radeon HD 5870就是在成熟的RV770架构基础上通过增加核心规格、几何单元、DirectX 11指令而成。虽然它完整支持DirectX 11,但它的架构较陈旧、几何计算单元数量少,因此几何性不够理想。
|
索泰GTX 480极速版显卡产品资料 | |
|
流处理单元数量 |
480个 |
|
显存类型 |
GDDR5/1536MB/384-bit |
|
核心频率 |
700MHz |
|
显存频率 |
3696MHz |
|
流处理单元频率 |
1401MHz |
|
接口类型 |
双DVI+MiniHDMI |
|
参考价格 |
3888元 |
而NVIDIA GF100是针对DirectX 11特别是曲面细分全新设计的图形架构,完整支持DirectX 11,在架构设计处于领先地位。基于GF100架构的NVIDIA GeForce GTX 480显卡的几何性能较强,在DirectX 11游戏和Benchmark中展现出了令人信服的实力。
从产品的实际表现方面来看,索泰GTX 480极速版在五个基于DirectX 11的游戏和应用测试中,在四个测试项目中都处于领先低位。综上所述,我们认为具备真DirectX 11架构的GeForce GTX 480显卡在当前的DirectX 11应用,特别是具备大量曲面细分计算的应用和未来的游戏中将如鱼得水,性能更加出色,这也符合未来图形核心的发展趋势。
![]() 性能出众,采用公版设计。
性能出众,采用公版设计。
![]() 发热量、功耗较高。
发热量、功耗较高。

